0x0 简介
TVM是目前比较热门的深度学习编译框架,本文对tvm的函数注册机制和执行机制进行介绍,这些函数作为在python和c++代码之间交互的接口,可以理解成python和c++之间有统一的command交互接口。理解了这个交互接口,对理解tvm从python到c++的完整执行流程有很大的帮助。
另外本文后面以opt_gemm.py为例子,对tvm的从python到c++的执行流程进行了分析。
0x1 函数注册
TVM中所有上下层交互函数都封装到PackedFunc中,并且所有函数都保存在下面所示的Manager中,每一个函数都封装在Registry中,通过string作为key可以找到注册的函数并调用。tvm中使用的函数为什么要这样设计呢?好处是可以从python调用到这些函数的时候可以用统一的接口,简化接口层代码的编写,只需要把函数名作为key从Manager中找到对应的函数并调用。
Registry的定义如下,Registry提供接口把函数都封装到PackedFunc类型的变量中,后面会详细介绍这些接口。
PackedFunc的定义如下。
PackedFunc内部使用std::function来保存函数对象。
TVMArgs提供了对函数参数的封装,可以包括多个参数。
TVMRetValue提供了对函数返回值的封装。
PackedFunc中的函数参数TVMArgs定义如下,可以支持可变长度的函数参数。
下面来分析在tvm中注册执行函数的具体执行流程,包括三种方式。
0x11 通过set_body_typed的注册
下图说明了通过set_body_typed来注册函数对象到Registry::Manager的详细过程。
下面是set_body_typed注册函数对象的举例说明。
relay模块中通过set_body_typed的注册方式来注册函数_make.relu。
注意这个函数内部还通过Op::Get()来得到op operator,这个op operator的管理在本文0x14小节中介绍。
|
|
relay模块依赖于topi层的实现,topi层中对relu的定义如下。
|
|
最后调用到lang模块中实现的tvm::max,构造出相应的TVM IR。
最后python模块中的relay层对relu的实现提供了python封装。这样python就可以调用到前面介绍的C++模块中的对应实现。
0x12 通过set_body_method的注册
下图说明了通过set_body_method来注册函数对象到Registry::Manager的详细过程。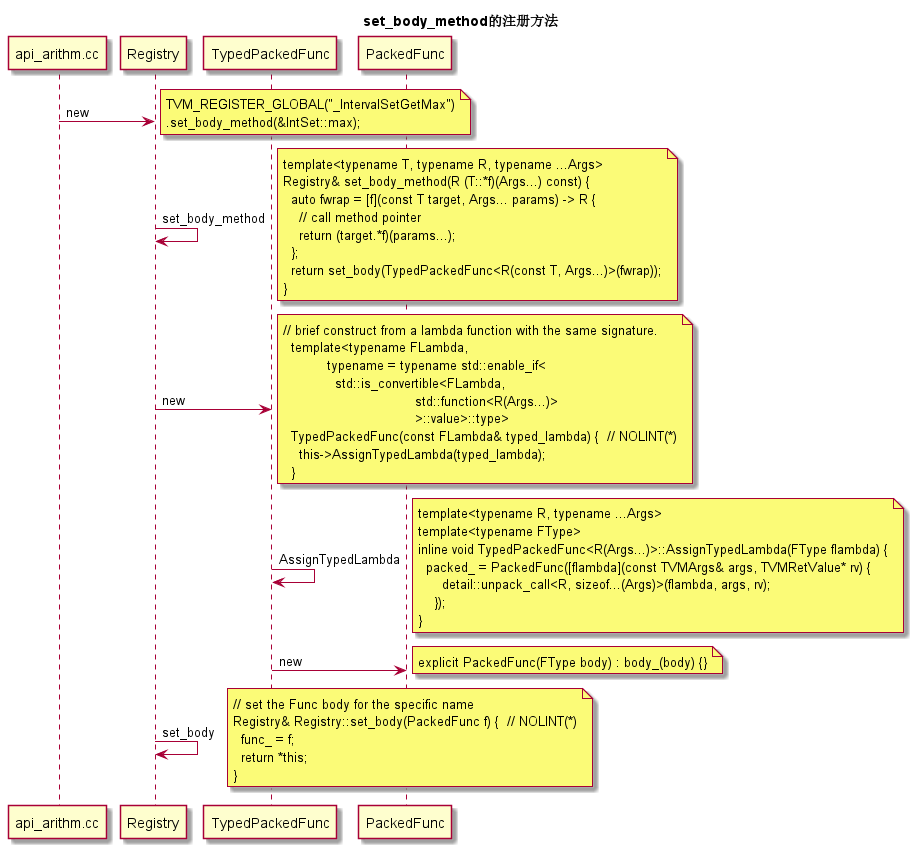
0x13 通过set_body的注册
下图说明了通过set_body来注册函数对象到Registry::Manager的详细过程。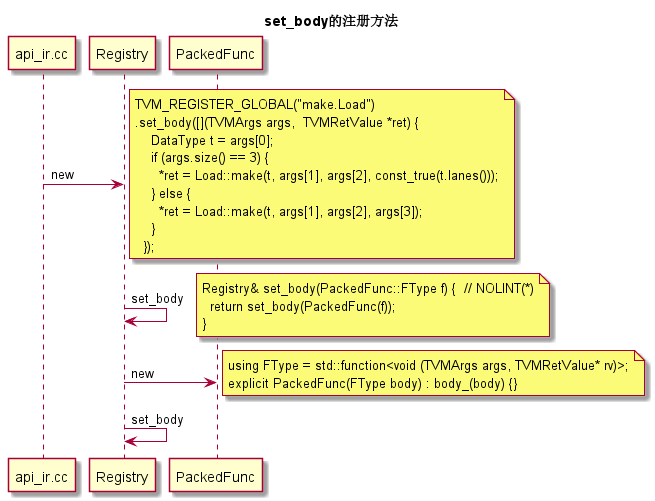
下面是一个set_body的调用示例。
0x14 Relay OP注册
Relay OP保存在另外一个OpManager中,和前面的函数注册不是一个地方,这是因为这个OpManager管理的是relay operator函数,这些函数不会直接从python中调用过来。
OpManager的相关代码如下。
下面是调用OpManager来注册op函数的代码示例。
如何取得OpManager中注册的op函数呢?答案是像下面这段代码所示通过调用Op::Get()来得到。
0x2 执行流程介绍
前面介绍了执行函数是如何注册的,那这些函数是怎样被python调用到的呢?下面来介绍一下。
我们知道从python调用过来的接口定义在c_runtime_api.h头文件中,这其中比较重要的是这两个API,TVMFuncCall()和TVMArrayAlloc,从API的名称上可知,TVMFuncCall对应于从python来的函数调用,TVMArrayAlloc对应于数组的分配。
这两个API接口定义如下。
然而python是如何知道前面的函数Manager中包括了哪些函数呢?这个时候Manager提供了一个函数供上层来调用得到所有注册函数名称列表,这个函数的定义如下。
然后python层根据前面的函数名称列表,通过下面的函数来得到每一个函数名称所对应的函数对象,python层拿到了这些函数对象以后,会在python层也创建相应的函数对象。这样python和c++层的函数操作就可以对应起来了。
在python中创建函数对象的代码如下,先根据函数TVMFuncGetGlobal()来查找底层的函数对象,找到以后根据返回的handle创建上层函数对象Function。
下面来介绍一下函数调用是如何从python层调用到C++层的,其中核心是要理解TVMFuncCall的调用过程。
0x21 TVMFuncCall的调用过程
Python中调用TVMFuncCall的代码如下所示,其中包括了函数参数的封装。
self.handle是python中持有的C++ PackedFunc对象。
从Python代码调用到C++代码的入口函数如下。
函数参数func是封装好的PackedFunc对象。
下面执行对body_的调用,利用可变参数模板的递归展开来实现,这样就可以调用到真正的注册函数了。
|
|
最后可以看到调用的是Variable::make来生成tvm IR。
|
|
0x22 TVMArrayAlloc的调用过程
TVMArrayAlloc的调用过程比较简单,直接调用NDArray的接口来分配Array。
0x03 opt_gemm.py执行流程分析
下面来分析tvm自带的矩阵优化测试程序opt_gemm.py的执行流程。
0x31 根据算法创建数据流图
python代码如下,这部分描述了算法是两个矩阵相乘,根据矩阵的大小分配了相应的占位符placeholder,placeholder和tensorflow中的概念类似。然后调用compute()函数创建tvm IR。
上面算法描述对应到C++代码中,会创建相应的tvm node,这部分可以理解成是tvm的IR的生成。
下面的代码描述了上述python流程执行的最后创建ComputeOpNode的过程。
0x32 创建Schedule
python代码如下。
对应的C++代码如下,这个时候会根据前面创建的tvm IR来生成reader graph,reader graph中描述了node之间的数据依赖关系。
0x32 用TVM Pass来处理schedule生成的graph
执行下面的测试代码以后会调用下面的语句来创建stmt。
func = tvm.build(s, [A, B, C], target=target, name=’mmult’)
其Python代码如下。
前面的ir_pass.xxx函数调用都会对应到C++的实现,这些pass是tvm中实现的中间流程处理操作,
例如前面的函数中执行的下列python代码,
stmt = ir_pass.RemoveNoOp(stmt)
其对应的C++代码如下所示。
|
|
0x33 把前面优化过的Pass调用LLVM codegen来生成LLVM IR
python代码如下。
C++代码如下,该段代码把tvm IR翻译成LLVM IR。
在其调用的Finish()函数中还会采用LLVM PassManager对已经生成的LLVM IR进行进一步优化。
0x34 根据LLVM IR生成对应的机器指令
调用了如下python代码就触发了机器指令的生成。
func(a, b, c)
func为前面返回的LLVM IR module对应的地址,a, b, c为对应的执行参数,也就是矩阵运算的输入。
对应到C++中的下述实现,调用LLVM模块来生成对应target的机器代码。
0x35 评估执行时间
python代码。
c++代码如下,调用LLVM生成的机器指令来执行具体的运算。这部分还包括了把运算调用到其他机器的rpc操作。